CVSS Frequently Asked Questions
What is CVSS?
A: CVSS stands for The Common Vulnerability Scoring System and is a vendor agnostic, industry open standard designed to convey vulnerability severity and help determine urgency and priority of response. It solves the problem of multiple, incompatible scoring systems and is usable and understandable by anyone.
Who developed CVSS?
A: CVSS was commissioned by the National Infrastructure Advisory Council (NIAC) tasked in support of the global Vulnerability Disclosure Framework. It is currently maintained by FIRST (Forum of Incident Response and Security Teams) http://www.first.org/. CVSS was a joint effort involving many groups including:
- CERT/CC
- Cisco
- DHS/MITRE
- eBay
- IBM Internet Security Systems
- Microsoft
- Qualys
- Symantec
Since the original release of CVSS, additional groups have joined the CVSS effort and assisted in developing version 2 of CVSS. The current list of major participants is available at www.first.org/cvss/team.
What does CVSS not do?
A: CVSS is not a threat scoring system (DHS color warning system), a vulnerability database or a real-time attack scoring system.
What is involved in CVSS?
A: The CVSS model is designed to provide the end user with an overall composite score representing the severity and risk of a vulnerability. It is derived from metrics and formulas. The metrics are in three distinct categories that can be quantitatively or qualitatively measured. Base Metrics contain qualities that are intrinsic to any given vulnerability that do not change over time or in different environments. Temporal Metrics contain characteristics of a vulnerability which evolve over the lifetime of vulnerability. Environmental Metrics contain those characteristics of a vulnerability which are tied to an implementation in a specific users environment.
What is the current version of CVSS?
A: The current version of CVSS is version 2. It was finalized and released to the public in June 2007. This FAQ addresses CVSS version 2 only, although there are many similarities between versions 1 and 2. Information on CVSS version 1 is available from the NIAC Paper on CVSS at http://www.first.org/cvss/v1/cvss-dhs-12-02-04.pdf.
What are the details of the Base Metrics?
A:There are six Base Metrics which represent the most fundamental, immutable qualities of a vulnerability.
a) Access Vector measures how remote an attacker can be to attack a target.
- Local: Exploiting the vulnerability requires either physical access to the target or a local (shell) account on the target.
- Adjacent Network: Exploiting the vulnerability requires access to the local network of the target.
- Network: The vulnerability is exploitable from remote networks.
b) Access Complexity measures the complexity of attack required to exploit the vulnerability once an attacker has gained access to the target system.
- High: Specialized access conditions exist, such as a specific window of time (a race condition with a very narrow window), specific circumstance (a configuration rarely seen in practice), or social engineering methods that would be easily detected by knowledgeable people.
- Medium: Somewhat specialized access conditions exist, such as a non-default configuration that is not commonly used or social engineering methods that might occasionally fool cautious users.
- Low: Specialized access conditions or extenuating circumstances do not exist. In other words, it is usually or always exploitable. This is the most common case.
c) Authentication measures the number of times an attacker must authenticate to the target system in order to exploit the vulnerability.
- Multiple: Two or more instances of authentication are required to exploit the vulnerability, even if the same credentials are used each time.
- Single: One instance of authentication is required to exploit the vulnerability.
- None: Authentication is not required to exploit the vulnerability.
d) Confidentiality Impact measures the impact on confidentiality of a successful exploit of the vulnerability on the target system.
- None: No impact on confidentiality.
- Partial: Considerable informational disclosure.
- Complete: Total information disclosure.
e) Integrity Impact measures the impact on integrity of a successful exploit of the vulnerability on the target system.
- None: No impact on integrity.
- Partial: Considerable breach in integrity.
- Complete: Total compromise of system integrity.
f) Availability Impact measures the impact on availability of a successful exploit of the vulnerability on the target system.
- None: No impact on availability.
- Partial: Reduced performance or interruptions in resource availability.
- Complete: Total shutdown of the affected resource.
What are the details of the Temporal Metrics?
A: There are three Temporal Metrics which represent the time dependent qualities of a vulnerability.
a) Exploitability measures how complex the process is to exploit the vulnerability in the target system.
- Unproven: No exploit code is yet available
- Proof of Concept: Proof of concept exploit code is available
- Functional: Functional exploit code is available
- High: Exploitable by functional mobile autonomous code or no exploit required (manual trigger)
b) Remediation Level measures the level of an available solution.
- Official Fix: Complete vendor solution available
- Temporary Fix: There is an official temporary fix available
- Workaround: There is an unofficial non-vendor solution available
- Unavailable: There is either no solution available or it is impossible to apply
c) Report Confidence measures the degree of confidence in the existence of the vulnerability and the credibility of its report.
- Unconfirmed: A single unconfirmed source or possibly multiple conflicting reports
- Uncorroborated: Multiple non-official sources; possibly including independent security companies or research organizations
- Confirmed: Vendor has reported/confirmed a problem with its own product, or an external event such as widespread exploitation confirms the existence of the problem
What are the details of the Environment Metrics?
A: There are three Environmental Metrics which represent the implementation and environment specific qualities of a vulnerability.
a) Collateral Damage Potential measures the potential for a loss of life or physical assets through damage or theft of property or equipment.
- None: There is no potential for loss of life, physical assets, productivity or revenue.
- Low: A successful exploit of this vulnerability may result in slight physical or property damage, or slight loss of revenue or productivity.
- Low-Medium: A successful exploit of this vulnerability may result in moderate physical or property damage, or moderate loss of revenue or productivity.
- Medium-High: A successful exploit of this vulnerability may result in significant physical or property damage or loss, or significant loss of revenue or productivity.
- High: A successful exploit of this vulnerability may result in catastrophic physical or property damage and loss, or catastrophic loss of revenue or productivity.
b) Target Distribution measures the percentage of vulnerable systems.
- None: No target systems exist, or targets are so highly specialized that they only exist in a laboratory setting (effectively 0% of the environment is at risk).
- Low: Targets exist inside the environment, but on a small scale (between 1% - 25% of the total environment is at risk).
- Medium: Targets exist inside the environment, but on a medium scale (between 26% - 75% of the total environment is at risk).
- High: Targets exist inside the environment on a considerable scale (between 76% - 100% of the total environment is at risk).
c) Security Requirements allows a score to be customized depending on the criticality of the affected IT asset, such as giving greater weight to availability if an asset supports a business function for which availability is most important. The Security Requirements consist of three metrics: confidentiality, integrity, and availability. The possible values for each metric are:
- Low: Loss of [confidentiality|integrity|availability] is likely to have only a limited adverse effect on the organization or individuals associated with the organization (e.g., employees, customers).
- Medium: Loss of [confidentiality|integrity|availability] is likely to have a serious adverse effect on the organization or individuals associated with the organization.
- High: Loss of [confidentiality|integrity|availability] is likely to have a catastrophic adverse effect on the organization or individuals associated with the organization.
How is the scoring done?
A: Scoring is the process of combining all the metric values according to specific formulas. Base Scoring is computed by the vendor or originator with the intention of being published and once set, is not expected to change. It is computed from the big three confidentiality, integrity and availability. This is the foundation which is modified by the Temporal and Environmental metrics. The base score has the largest bearing on the final score and represents vulnerability severity.
Temporal Scoring is also computed by vendors and coordinators for publication, and modifies the Base score. It allows for the introduction of mitigating factors to reduce the score of a vulnerability and is designed to be re-evaluated at specific intervals as a vulnerability ages. The temporal score represents vulnerability urgency at specific points in time.
Environmental Scoring is optionally computed by end-user organizations and adjusts combined Base-Temporal score. This should be considered the FINAL score and represents a snapshot in time, tailored to a specific environment. User organizations should use this to prioritize responses within their own environments.
Is there an easier way to understand all this?
A: Yes. This flowchart shows each metric group and how they interrelate with each other.
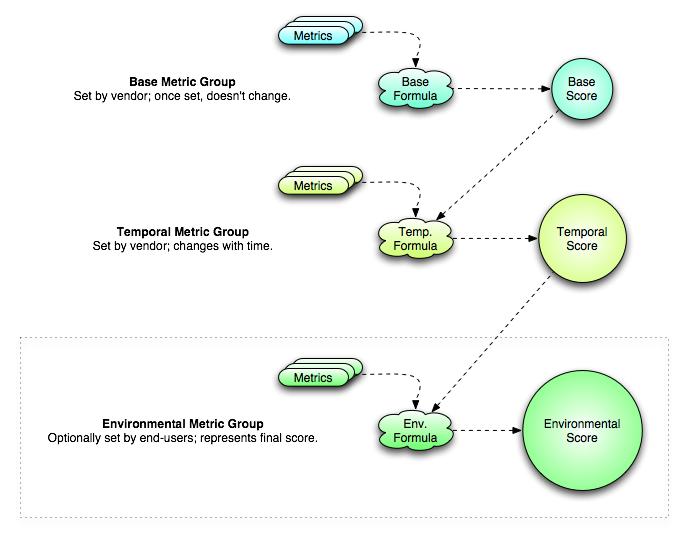
A: Full details on the CVSS version 2 formulas are available from A Complete Guide to the Common Vulnerability Scoring System Version 2.0, at http://www.first.org/cvss/cvss-guide.html.
Who is using CVSS?
A: NIAC was submitted to the President in January 2005. DHS (Department of Homeland Security) and CVSS developers are encouraging widespread, voluntary adoption. Many organizations have since adopted CVSS, including several NIAC member companies (Akamai, American Water, Symantec, Union Pacific) and other organizations (CERT/CC, Cisco, HP, IBM, NIST, Oracle, Qualys, US-CERT).
I am an end-user (CISO/CSO/operations security person), is there anything I need to do?
A: Typically, application and security product vendors will provide both the Base and Temporal scores. As the end user, you need only calculate your Environmental score.
I am an application or product security vendor, why should I use CVSS and publish CVSS temporal scores?
A: As more vendors begin publishing CVSS scores, more customers will understand and appreciate the advantages. They will grow to appreciate the ability to tailor scores to their environment and begin expect CVSS scores of all their suppliers. The more it is used, the better it works.
I am an end-user, and really like other vendors scoring methods, why should I change to CVSS?
A: Other systems are closed competing standards, do not offer a mutable scoring framework, and do not consider different environments.
What does CVSS really offer that other scoring methodologies do not?
A: An open framework that can be used, understood, and improved upon by anybody to score vulnerabilities.
Where can I get CVSS scores?
A: There are many sources of CVSS scores. Several major sources of CVSS scores are posted at http://www.first.org/cvss/scores.html.
Where can I get the CVSS code?
A: CVSS is a framework that you can use to develop an application suitable to your needs, your environment or your customers. There is no established code as of yet. However, there are several CVSS calculators available; a listing of some calculators is posted at http://www.first.org/cvss/scores.html.
How can I help establish CVSS throughout the industry?
A: Urge your vendors to support CVSS scoring.
A: You can get more information at FIRST, the current custodian for CVSS at http://www.first.org/cvss. Documentation on CVSS metrics, formulas, and scoring is available at http://www.first.org/cvss/cvss-guide.html.
By Karen Scarfone
The purpose of this writeup is to explain how the CVSS v2 formulas and metric values were established. Much of that process is documented in the CVSS-SIG Version 2 History publication, available at http://www.first.org/cvss/history. However, this publication primarily lists the intermediate drafts of the formulas and metrics, and does not always explain the work that went into each draft. So this writeup is intended to supplement the history publication.
The CVSS-SIG had identified several shortcomings in CVSS v1. There was a lack of diversity in scores--too many vulnerabilities with different characteristics each receiving the same score, when in many cases there was consensus that one vulnerability was significantly more severe than another (and should have had a higher score). Overall, many vulnerabilities had lower scores than the SIG members would have expected, and for some types of vulnerabilities they were scored significantly lower than other vulnerabilities that were considered less severe. Additional problems with the v1 specification were identified by comparing scores calculated by multiple organizations' analysts; discussions regarding differences in scoring identified unclear language in the specification.
After the problems were enumerated, they were resolved using a combination of two methods. One was to revise the metrics, such as adding more possible values for the AccessComplexity, AccessVector, and Authentication metrics (each went from 2 to 3 possible values). The impact bias metrics were moved from the base score to the environmental score. Wording changes were made to all the metric descriptions. These changes were intended to improve score diversity and make scoring more consistent across organizations performing scoring. The changes to the metrics and their descriptions are listed in Proposals 1-11 in Appendix A of the history publication.
The second method used to address the problems was a revamping of the formulas and metric values. This was necessary in part because of the changes to the base metrics (additional possible values for metrics, plus the removal of the impact bias metrics). But it was also necessary because the existing formulas and values were generating scores that were not capturing the relative differences in severity among vulnerabilities. Initial efforts involved determining if the existing formulas and values could simply be tweaked a bit to address the identified scoring problems, but a reasonable solution could not be found. Statisticians reviewed the original formula and determined that much of the reason for the too-low scores from CVSS v1 was the highly multiplicative nature of the original formula. A single metric with a low value could cause a score to be lowered by 3 or 4 points, and a few metrics with non-high values would cause scores to become quite low. So the decision was made to develop a new formula that would not have these characteristics.
To start over, we wanted to list the possible vectors and assign scores to all of them, then develop a formula that would produce those scores. However, this was not feasible because there are 702 possible vectors (3^6 minus the 27 cases where there is no impact). Differentiating the severity of 702 vectors and achieving consensus on their scores is not realistic. Then we had a "eureka" moment when we realized that the six metrics could be split into two groups, because three related to impact and three to exploitability. This gave us two sub-vectors, one with 27 possibilities and one with 26 possibilities (3^3 minus the 1 case where there is no impact). We then developed a series of rules to set the order of the possible values for each sub-vector. These rules are listed in Appendix C of the history publication. An example of a rule is "Vectors with 2 'Complete' components must be rated higher than those with no 'Complete' components." The ordered subvectors produced by these rules were reviewed by the SIG and some minor changes made to the ordering--so while the rules are mostly consistent with the actual ordering of CVSS v2 scores, they are not fully consistent.
The next step was to take the ordered subvectors, assign scores to them, and develop formulas based on these scores. There were many iterations of the metric values and formulas, many of which are listed in Appendices D through M of the history publication. A key element of the new formula is described in Proposal 12 of Appendix A, namely the relative weightings for the impact and exploitability vectors. An analysis of CVSS v1 showed that in effect it gave weightings of 0.572 and 0.428 to impact and exploitability, respectively. Application of these weights to our subvectors and subvector scores produced reasonable base scores, so we simplified the weightings to 0.6 and 0.4, respectively.
At one point we discussed having a lookup table for the scores--there could be a lookup table for each subvector, and the two subvector scores then combined using the 0.6/0.4 weightings. However, consensus was that people would prefer a formula to lookup tables, so we worked on developing a formula that would approximate the lookup table values, with a reasonably small margin of error (less than 0.5, if I remember correctly). After each new formula was developed, it would be applied to common vectors and the resulting scores analyzed to determine how close they were to the desired values. There were also problems found with values going higher than the ceiling of 10, so the formula had to be modified to ensure that no value went over 10. The final version of the formula and the metric values was used for CVSS v2.

")