Usage
What is EPSS, and what is it not?
EPSS is a measure of exploitability. Specifically, EPSS is estimating the probability of observing any exploitation attempts against a vulnerability in the next 30 days. This is accomplished by observing and recording exploitation attempts against vulnerabilities and then collecting as much information as we can about each of those vulnerabilities. Since EPSS is estimating the probability of exploitation activity, EPSS is best used when there is no other evidence of active exploitation. When evidence or other intelligence is available about exploitation activity, that should supersede the EPSS estimate (see “Everyone knows this vulnerability has been exploited…” question).
EPSS is only estimating the probability that a vulnerability will be exploited. EPSS does not account for any specific environmental, nor compensating controls, nor does it make any attempt to estimate the impact of a vulnerability being exploited. EPSS is not, and should not be treated as a complete picture of risk, but it can be used as one of the inputs into risk analyses. For a visual representation of this we turn to the Open Group Standard: Risk Analysis (O-RA), specifically Figure 2 titled, "Decomposing an Open FAIR Loss Event". We have modified the original image to annotate where the strength of EPSS lies within a risk analysis framework..
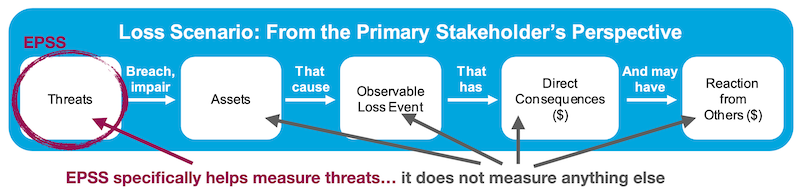
The above picture is showing that EPSS will help measure the threat associated with a published CVE, the rest of the considerations for a complete risk analysis should rely on existing or alternative methods.
Where do I get EPSS scores?
There are two methods for getting EPSS scores. First a daily downloadable CSV with all the CVEs may be downloaded from a direct HTTP request from the data and statistics page. Second, an API exists and is documented at https://api.first.org/epss/.
As a practitioner where do I start with EPSS? How do I use it?
EPSS is helpful in a variety of ways, so specific advice may be difficult. But first and foremost, get the data that EPSS is producing. It is refreshed every day and for each published CVE. EPSS produces a probability of exploitation activity (a value between 0 and 1) in the next 30 days, which is the primary EPSS score. EPSS also puts that score in context by producing the percentile, which is the proportion of vulnerabilities that are scored at or less than the vulnerability. The EPSS values can be used as an initial prioritization tool for observed vulnerabilities in your environment, it can help assess the chance that any particular vulnerability will experience exploitation activity in the wild.
How is EPSS different from CVSS? Should this be used with, or replace, CVSS?
Both EPSS and CVSS seek to help network defenders better prioritize vulnerability management. Both efforts are run by volunteer groups of researchers, practitioners, academics and government personnel. And the scores from both efforts are made available to the public at no cost.
EPSS is a measure of threat – it estimates the probability that a vulnerability will experience exploitation activity in the wild. It accomplishes this entirely by data-driven, empirical analysis. Because EPSS produces a probability, it can scale to estimate the probability that at least one out of a larger set of vulnerabilities may be exploited . That larger set could represent all vulnerabilities on a laptop, network appliance, subnet, or an entire office location.
CVSS, on the other hand, is thought of as a measure of overall “severity” of a vulnerability. The CVSS Base metrics are evaluated based on the immutable properties of a vulnerability. Those values are then transformed into numerical form, and then an equation is used to approximate the rank ordering of vulnerability severity. CVSS cannot be used to combine the scores of multiple vulnerabilities.
As for how to use EPSS together with CVSS, this is a complicated question, with many possible answers. Please see user guide article for a more complete discussion.
Is there an offline EPSS calculator?
Short answer: No. The second version of EPSS is built on hundreds of variables and is no longer implementable as a simple calculator. However, we have had enquiries for the ability to score vulnerabilities that do not yet have an assigned CVE ID. If you have a use case for that kind of scoring, please reach out and let us know. EPSS is constantly evolving and improving, please consider getting involved!
What does the EPSS score mean? How should I interpret the probability EPSS produces?
EPSS is a probability of observing exploitation one or more days of exploitation activity in the next 30 days. Please see Understanding EPSS Probabilities and Percentiles for a more complete discussion.
Can I use this in my commercial product? What Licensing limitations exist?
We grant the use of EPSS scores freely to the public, subject to the following conditions. We reserve the right to update the model and these webpages periodically, as necessary, though we will make every attempt to provide sufficient notice to users in the event of material changes. While membership in the EPSS SIG is not required to use or implement EPSS, we ask that if you are using EPSS, that you provide appropriate attribution where possible. EPSS can be cited either from this website (e.g. "See EPSS at https://www.first.org/epss), or as: Jay Jacobs, Sasha Romanosky, Benjamin Edwards, Michael Roytman, Idris Adjerid, (2021), Exploit Prediction Scoring System, Digital Threats Research and Practice, 2(3)
Are there any case studies for EPSS use?
We have not formalized any case studies for implementing and using EPSS. If you are leveraging EPSS, consider contributing your story back to the security community!
How can I participate / contribute data?
If you have suggestions, requests, would like to participate in the group, or discuss opportunities to collaborate by sharing exploit data that you see, please send us an email at epss-chairs@first.org.
EPSS Internals
The EPSS score for CVE-20XX-XXXX is higher/lower than I think it should be, why is that?
The practical -- though probably less satisfying answer -- is that any model is going to provide results based on averages of everything it sees. So yes, it is certainly possible (and probably expected) that for any particular vulnerability, the EPSS score may not match one's expectations of what we think it should be, or what one organization has seen on its network. But the hope is that overall, when we look at more and more CVEs with the same set of features, that the EPSS score will tend toward the actual probability (the ground truth).
But again, because EPSS is entirely data driven, any results are based off of what it actually sees in the wild, and not based on subjective or human intuition. !
Everyone knows this vulnerability has been exploited, why doesn’t EPSS score it at 100%?
EPSS should be thought of as pre-threat intelligence. Our detection systems, and by extension our threat intelligence, only report what they are programmed to look for, and then only what they can observe. For any given time period, vulnerability feeds can only describe a vulnerability in one of two ways, either it is known to be actively exploited or we don’t know because we haven’t observed exploitation, and absence of evidence is not the evidence of absence. If there is evidence that a vulnerability is being exploited, then that information should supersede anything EPSS has to say, because again, EPSS is pre-threat intel. If there is an absence of exploitation evidence, then EPSS can be used to estimate the probability it will be exploited. In other words, EPSS works best just below the obvious.
Having set that groundwork, there are two ways we have considered infusing threat intelligence information into EPSS. The first is after the model generates a probability we could modify the output if we see evidence of exploitation. The challenge is just how we would modify it. Just because we saw evidence of exploitation at some point in the past does not guarantee exploitation in the future. Modifying the score up to 100% would certainly overstate the exploitability of some vulnerabilities since not all vulnerabilities are 100% exploited in the future. This pushes us into the territory of producing a “magic number” that doesn’t have much basis in science and will move EPSS away from being purely data-driven.
The second way we could infuse threat intelligence is by using them in an autoregressive model (explicitly including one or more variables for previous exploitation activity). Right now, exploitation activity is the target variable and we use things like “is this remotely exploitable?” and “would this allow code execution?” as the features in the model to help us understand just how exploitable a vulnerability is expected to be. In simpler terms, currently exploitation activity is only on the left side of the equation and everything else about the vulnerability is on the right side. We use the right side of the equation to predict the left side (exploitation activity). By putting in an autoregressive variable for exploitation, we would include something like “how often was this vulnerability exploited in the last 7 days?” on the right side of the equation (the features or independent variables of the model).
We have tried this approach with several variations. But remember that vulnerabilities are reported in one of two states, either it is exploited or we don’t know if it’s exploited. The challenge is the model assumes the two states are binary and opposite: exploited or not. The outcome is that the model learns to rate the vulnerabilities where we do not know if exploitation is occurring very low. Previous exploitation becomes such a strong indicator that the other variables become much less important. The outcome is that EPSS would become reactionary rather than predictive. Any vulnerability without observed and recorded exploitation activity would receive a low probability of future exploitation. This goes counter to our goal with EPSS to be pre-threat intel, and to distinguish between vulnerabilities that are likely versus unlikely to be exploited.
The net result is EPSS is pre-threat intel and works bets just below the obvious. It should be treated as a strength that it factors in the attributes and threat environment for vulnerabilities rather than just looking up the CVE ID for past exploitations. If you have evidence of active exploitations, leverage that, for everything else, you have EPSS.
Why is the latest EPSS model using a binomial XGBoost model instead of other possible approaches, such as logistic regression, survival analysis, or neural networks?
The short answer is that the modeling behind the EPSS has gone through multiple iterations since we began. EPSS v1 specified a simple logistic regression using Elastic Net for variable selection, because we wanted to keep the approach as simple as possible, and be implemented in multiple environments including offline spreadsheets. Logistic regression provided a straightforward estimate of the probability that a vulnerability would ever be exploited, and the marginal effects of the covariates (aka explanatory variables or features) were clear.
However, the EPSS SIG has given priority to data fitting and accuracy and so EPSS is currently estimated using binomial XGBoost because it outperforms other modeling approaches.
To understand the long answer, however, let us separate a few related points: 1) the form of the research question being addressed, 2) the class of appropriate model specifications, and 3) variable selection.
Research Question
The structure of our data reflects binary outcomes about whether a vulnerability is observed to be exploited on a given day, or not. And so there are multiple conceptual approaches to specifying and estimating data like these, for example, as a probability estimation (i.e. what is the probability that a vulnerability will be exploited, conditional on a set of features?), or as survival analysis (i.e. what is the time to exploitation, conditional on a set of features?). Each of these conceptual approaches drives a different set of model choices and specifications.
Model Specification
Answering the first modeling approach (estimating probabilities) could be done with parametric OLS, logit, probit, poisson, or other nonparametric machine learning models. The simpler parametric models like OLS, logit/probit are preferred when interpreting the marginal effect of the covariates is most important. For example, understanding the marginal change in probability of a Microsoft vulnerability being exploited, vs a non-Microsoft vulnerability. These models are simple to run and review, but, as we've learned, do not provide the best fit for the data, and so would not provide the most accurate predictions of exploitation.
On the other hand, survival analysis speaks to estimating the time until one or more events, like exploitation, occur (the survival), or alternatively the probability that a vulnerability will be exploited, conditional on not having been exploited so far (the hazard). Survival analysis could be performed with any number of models, such as Cox regressions, Kaplan-Meier, or other accelerated failure time models, (see this link). These survival models can be appropriately used in our case even with multiple events (a vulnerability being exploited multiple times), censored data (e.g. vulnerabilities that are never exploited), and with time changing covariates (e.g. in cases where we think that the probability of exploitation for a certain kind of vulnerability changes with time).
We mentioned that the raw data provide information about which vulnerabilities are exploited on which days. However, for EPSS v2, we wanted to answer what we believe is the most practical question for network defenders: what is the probability that the vulnerability will be exploited in the next 30 days?
In order to best answer this question, we chose to reshape the data from daily binary (yes/no) values for each vulnerability, to instead create count values indicating the number of times a vulnerability was exploited within a 30 day window. In this sense, the data would now represent a number of events (trials) occurring during the time period. The creation of this new count/period data structure suggested that we could use other model specifications such as a poisson, or binomial regression.
We experimented with a poisson specification, however, we found that a binomial specification using an XGBoost estimator produced the best fit of the data, and therefore achieved the best performance. We also continue to experiment with various neural networks, but again (and to our surprise) they did not outperform the XGBoost approach, but this research offers an explanation for why we are seeing this type of result.
Variable Selection
With any estimating regression model, the selection of variables is important, and depending on one's purpose is either driven entirely by the researcher and research question (such as with econometric modeling), or through automated variable selection (such as is done in data science disciplines).
In EPSS v1 we used ElasticNet as the method for selecting the most important variables (i.e. those variables most correlated with the outcome). Variable selection in EPSS v2 is taken care of by XGBoost.
Feel free to ask us any questions about the modeling approach, what we tried but didn’t work, or why we’re using what we do. Email us at epss-chairs@first.org.
How can we trust EPSS? Why should I trust the score from EPSS?
EPSS is built using commonly-used statistical modeling techniques. We are leveraging established statistical methods as we collect and prepare the data as well as building, testing and validating the modeling within EPSS. We also validate the output of the model with real world observations. While this may seem impossible since we are always predicting the future, we can validate EPSS by training our models up to some point in history where we have data before and after that time. Once we generate a model up to some point, we can measure how it would have performed in “the future.” By using variations of that (for example holding out a subset of CVEs from the model building), we can estimate how well EPSS may perform in reality. See the EPSS model page for a discussion of EPSS performance.
Who is responsible for the daily operations for EPSS?
EPSS is driven by volunteers, and so many of the people involved with EPSS are tasked with the daily and ongoing operations of EPSS. Currently, the storage, computing and ongoing maintenance is hosted by the cybersecurity research company, Cyentia, where one of the EPSS co-chairs is a co-founder and Chief Data-Scientist. The API is being hosted by FIRST.
How much of the collection and scoring process is automated vs needing human interaction?
In the daily operations, EPSS is 100% automated. The data feeds are gathered and aggregated automatically and typically on a daily basis, once aggregated, CVEs in a published state in the CVE List at CVE.org will be scored automatically based on the information at hand. The onboarding of new data sources and model updates are currently 100% manual and performed by members of the data team on the EPSS SIG.
How are CVEs scored? How are the scores derived?
This question is relatively difficult to answer, but EPSS is a model of real world observations that was built to allow for interaction effects, so any single variable can have different influences depending on the context. See the explanation of the model here.
Can I look at the underlying data/model/code?
At this time we are not sharing the underlying data, model and/or source code. One limitation specifically around sharing data is that we have several commercial partners who requested that we not share as part of the data agreement. As far as the model and code, there are many complicated aspects to the infrastructure in place to support EPSS. We are constantly working on updates and additional offerings and improving transparency is one of our goals, but our primary goal remains to produce the most accurate estimates of exploitability, openly and freely to you.
How often are EPSS scores generated, how often is the model updated, and what is the difference?
EPSS scores are currently generated daily, and made available here. At a minimum, we expect to update the model twice a year, though we hope to update quarterly. By “updating the model” we mean that we would refresh all of the underlying data and create a new model that can re-learn what’s going on with the exploitation activity and pick up on any trends or shifts in exploitation activity since the last update.
What is the release history of EPSS?
EPSS was first released in April 2021, and version 2 was released February 4th, 2022.
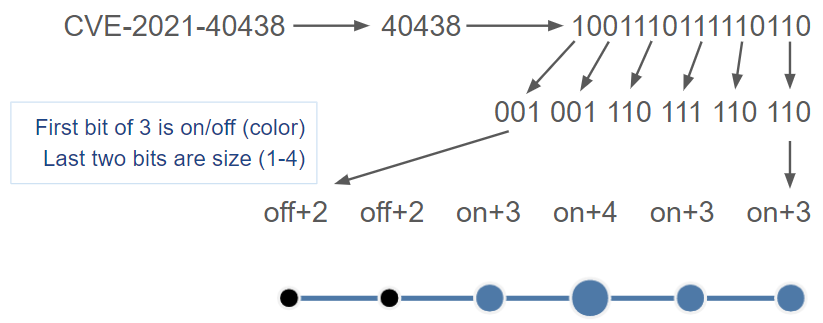
That EPSS logo is amazing, tell me more about how it's encoded!
Thanks, we're pretty proud of it ourselves. Here's the solution to the encoding: